

JAKARTA - Kecerdasan buatan terbaru Google DeepMind, DeepNash telah mempelajari cara mengalahkan hampir semua pemain manusia di permainan perang, Stratego. Menjadikannya sebagai salah satu pemain teratas di dunia.
Stratego merupakan permainan dengan melibatkan dua pemain yang berusaha merebut bendera musuh. DeepNash diajari cara bermain Stratego, yang mencoba mencari tahu masing-masing dari 40 bidak permainan lawan mereka yang berada di lokasi tersembunyi di seluruh papan.
Karena kerumitan Stratego, DeepNash mengambil pendekatan tanpa model untuk algoritme mereka. Di sini, AI tidak mencoba memodelkan perilaku lawannya dengan tepat, semacam batu tulis kosong untuk dipelajari.
Pengaturan itu sangat berguna pada tahap awal permainan, ketika DeepNash hanya mengetahui sedikit tentang bidak lawannya, itu membuat prediksi sangat sulit.
Tim DeepMind kemudian menggunakan pembelajaran penguatan mendalam untuk menggerakkan DeepNash, dengan tujuan menemukan keseimbangan permainan. Seperti pembelajaran penguatan yang membantu memutuskan langkah terbaik selanjutnya di setiap langkah permainan, sementara DeepNash menyediakan strategi pembelajaran secara keseluruhan.
Untuk mengevaluasi sistem, tim juga merekayasa tutor menggunakan pengetahuan dari gim untuk menyaring kesalahan nyata yang mungkin tidak masuk akal di dunia nyata.
Menurut tim DeepMind, Stratego adalah permainan informasi yang tidak sempurna dan mengharuskan setiap pemain untuk menyeimbangkan semua kemungkinan hasil saat membuat keputusan, menjadikannya permainan yang jauh lebih kompleks daripada catur, Go atau poker, yang juga telah dipelajari oleh DeepMind AI sebelumnya.
Secara angka, Go memiliki sepuluh pangkat 360 kemungkinan status permainan, jauh lebih banyak daripada poker atau catur sementara Stratego memiliki sepuluh pangkat 535.
BACA JUGA:
-
 | TEKNOLOGI
| TEKNOLOGI
Sam Bankman-Fried Curi Uang Pengguna FTX untuk Danai Alameda Research, Kata CEO Coinbase
06 Desember 2022, 16:06 -
 | TEKNOLOGI
| TEKNOLOGI
Menuju 2023, Meta Indonesia Siapkan Tiga Poin Penting di Platformnya
06 Desember 2022, 15:37 -
 | TEKNOLOGI
| TEKNOLOGI
Elon Musk Tak Sendiri, Spotify dan Epic Games Jadi Sekutu Twitter Perang Lawan Apple
30 November 2022, 07:30


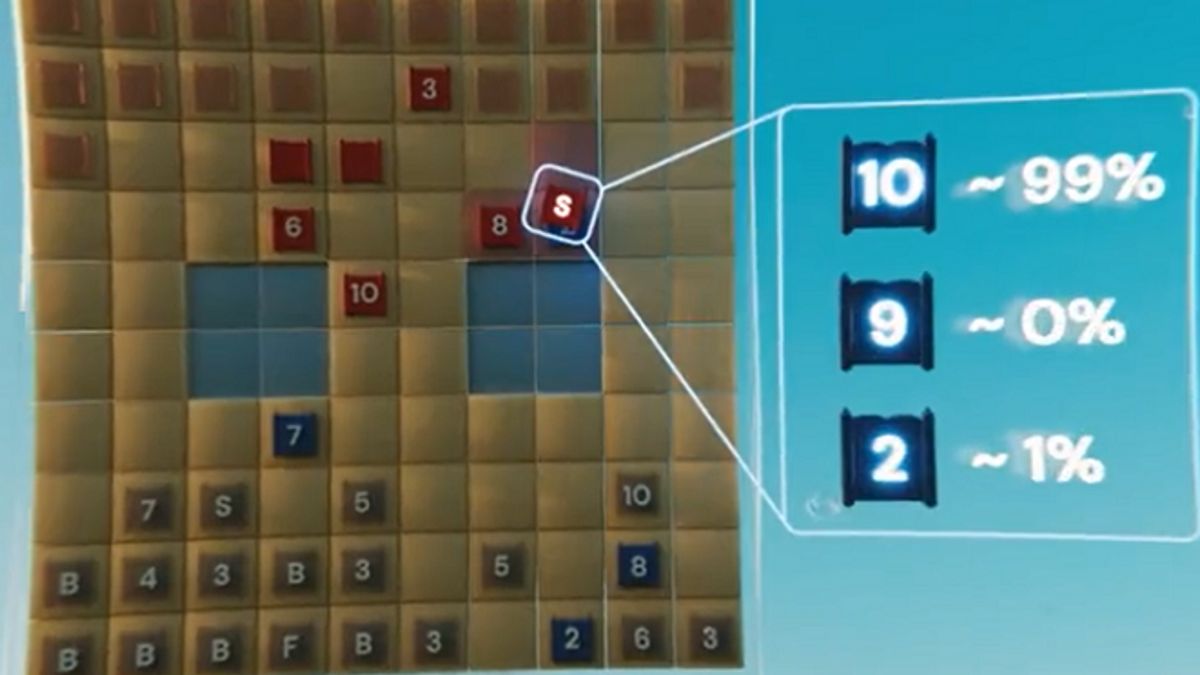
Tim DeepMind menyatakan, DeepNash menjadi sangat baik di Stratego sehingga mencapai peringkat tiga teratas sepanjang masa di antara pemain manusia di platform Stratego online terbesar di dunia, Gravon.
"Tingkat permainan DeepNash mengejutkan saya," ujar salah satu penulis makalah baru tentang AI yang diterbitkan dalam jurnal Science, Vincent de Boer, yang juga mantan Juara Dunia Stratego.
Melansir Futurism, Selasa, 6 Desember, AI mengembangkan strategi yang tidak dapat diprediksi untuk memastikan lawan manusianya terus menebak-nebak, yang melibatkan penyebaran umpan untuk menyingkirkan mereka dari jalurnya.
Bahkan, AI belajar bagaimana menggertak lawannya dengan memainkan bidak peringkat rendah seolah-olah itu jauh lebih berharga.
"Saya belum pernah mendengar tentang pemain Stratego artifisial yang mendekati level yang dibutuhkan untuk memenangkan pertandingan melawan pemain manusia yang berpengalaman," tutur Boer.
Tag Terpopuler
#prabowo subianto #kpk #ramadan #paus fransiskus #danantara #indonesia gelapPopuler