

ジャカルタ-マイクロソフトは、人工知能(AI)ベースの音声シミュレーターを発売したばかりで、わずか3秒で人の声を聞いた後、人の声を正確に模倣することができます。
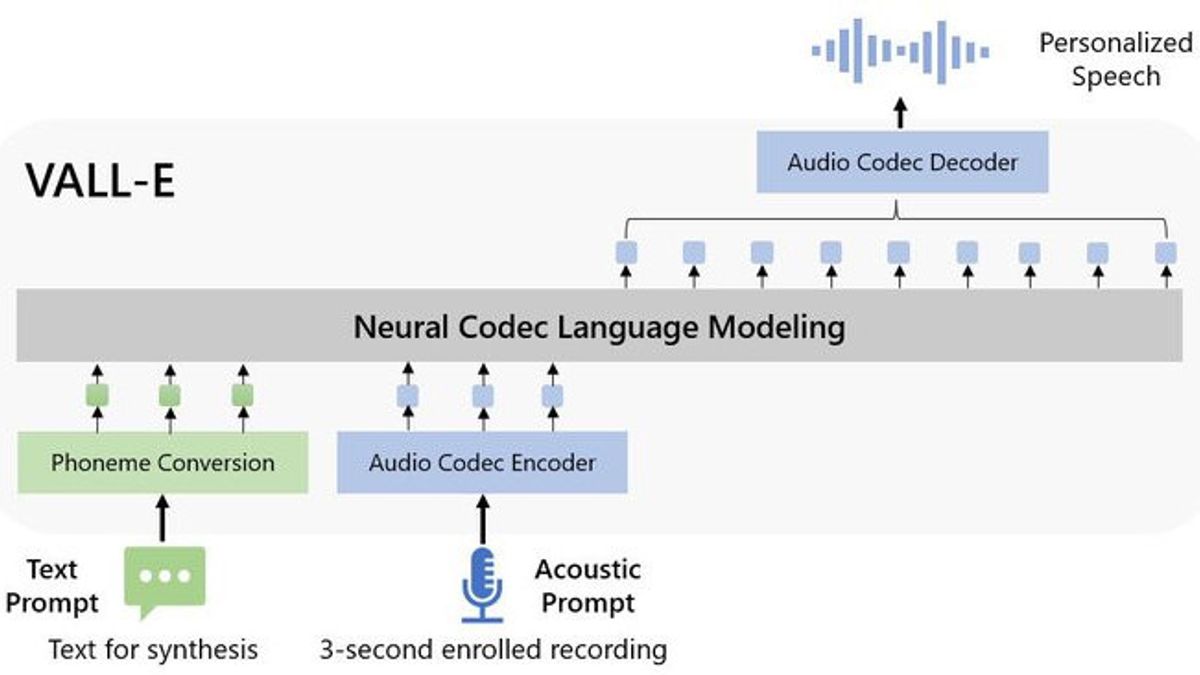
VALL-Eと呼ばれるこのニューラルコーデックディスカッションモデルは、AIによって駆動される高度なテキスト読み上げ(TTS)システムです。このシステムは、3秒間の声のサンプルのみに基づいて、誰と同じように話すようにトレーニングできます。
「具体的には、すぐに使用できるニューラルオーディオコーデックモデルから派生した離散コードを使用してVALL-Eをトレーニングし、TTSを以前の研究のような連続的な信号回帰ではなく、条件付き言語モデリングタスクと見なしました」とMicrosoftの研究者は述べています。
その結果、TTSシステムは、既存のシステムとはまったく異なるアプローチをとる非常に自然に聞こえます。
さらに、VALL-Eは人間のようにリアルに聞こえ、これまで以上にトーンや感情を伝えることができます。しかし、懸念があります, システムがディープフェイクオーディオに使用される可能性があること.
VALL-Eは、パブリックドメインのオーディオブックを含む、何千人もの人々からの60,000時間のオーディオ入力を使用して作成およびトレーニングされています。VALL-Eは、短いサンプルを使用して、以前は不可能だった方法で音のトーンと音色を模倣することができます。
「事前トレーニング段階では、TTSトレーニングデータを既存のシステムの数百倍の6万時間の英語音声に増やしました」とMicrosoftの研究者は述べています。
「VALL-Eは、コンテキストで学習能力を呼び起こし、アコースティックプロンプトとして目に見えないスピーカーのわずか3秒間の登録録音で高品質の個人的なスピーチを合成するために使用できます」と彼は付け加えました。
1月11日水曜日にベータニュースを立ち上げたマイクロソフトの研究チームは、実験結果は、VALL-Eが音声の自然さと話者の類似性の点で高度なゼロショットTTSシステムを大幅に上回っていることを示したと付け加えました。
「さらに、VALL-Eは、合成の音響プロンプトからスピーカーの感情と音響環境を保持できることがわかりました」とMicrosoftの研究チームは述べています。
The English, Chinese, Japanese, Arabic, and French versions are automatically generated by the AI. So there may still be inaccuracies in translating, please always see Indonesian as our main language. (system supported by DigitalSiber.id)








