

أطلقت شركة مايكروسوفت للتو محاكيا صوتيا قائما على الذكاء الاصطناعي (الذكاء الاصطناعي) ، وهو قادر على تقليد صوت الشخص بدقة بعد الاستماع إليه وهو يتحدث في ثلاث ثوان فقط.
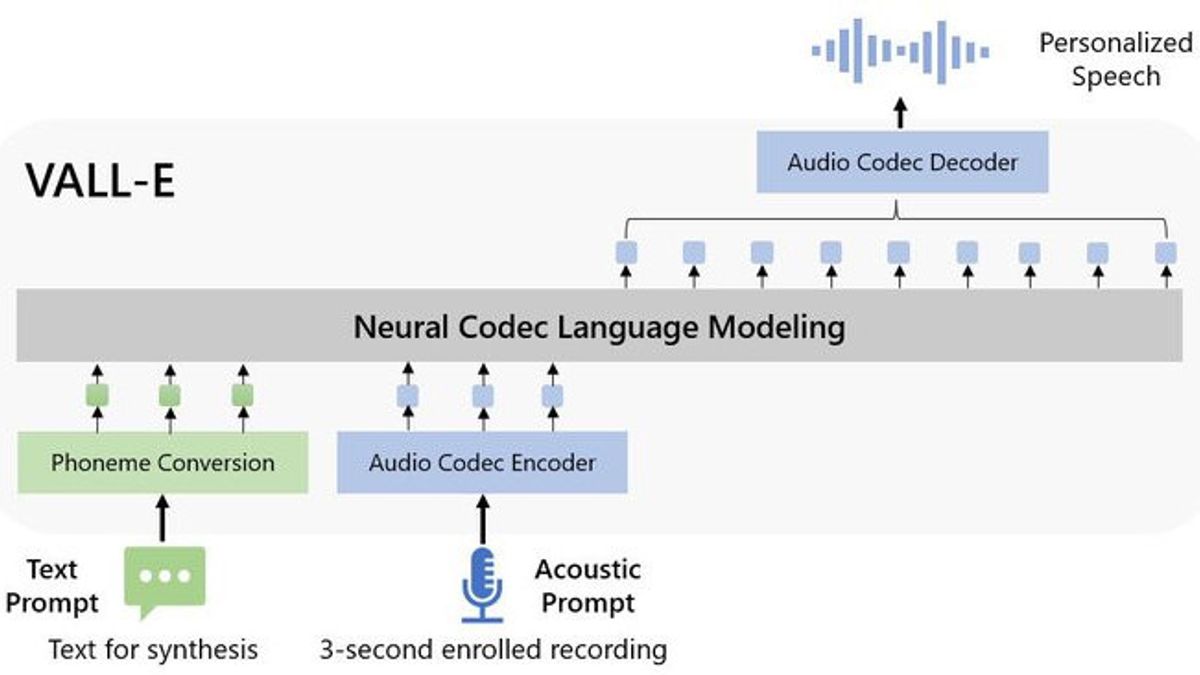
يطلق عليه اسم VALL-E ، نموذج مناقشة برنامج الترميز العصبي هذا وهو نظام متقدم لتحويل النص إلى كلام (TTS) مدفوع الذكاء الاصطناعي. يمكن تدريب النظام على التحدث مثل أي شخص بناء على عينة مدتها ثلاث ثوان فقط من صوته.
"على وجه التحديد ، قمنا بتدريب VALL-E باستخدام رمز منفصل مشتق من نموذج ترميز صوتي عصبي جاهز للاستخدام ، واعتبرنا TTS مهمة نمذجة لغة مشروطة بدلا من انحدار الإشارة المستمر كما في العمل السابق" ، قال باحثو Microsoft.
نتيجة لذلك ، يبدو نظام TTS طبيعيا جدا مع اتباع نهج مختلف تماما عن النظام الحالي.
بالإضافة إلى ذلك ، يبدو VALL-E أيضا واقعيا مثل الإنسان ، حيث يمكنه نقل النغمات والعواطف بشكل أفضل من أي وقت مضى. ولكن هناك مخاوف من إمكانية استخدام النظام لصوت التزييف العميق.
يتم إنشاء VALL-E وتدريبه باستخدام 60000 ساعة من المدخلات الصوتية من آلاف الأشخاص ، بما في ذلك الكتب الصوتية في المجال العام. من خلال العمل مع عينة موجزة ، فإن VALL-E قادر على تقليد نغمة الصوت وجرسه بطريقة كانت مستحيلة في السابق.
قال الباحث في مايكروسوفت: "خلال مرحلة ما قبل التدريب ، قمنا بزيادة بيانات تدريب TTS إلى 60 ألف ساعة من الكلام باللغة الإنجليزية وهو أكبر بمئات المرات من النظام الحالي".
وأضاف: "يستحضر VALL-E قدرات التعلم في السياق ويمكن استخدامه لتجميع خطاب شخصي عالي الجودة من خلال تسجيل مسجل مدته 3 ثوان فقط لمكبر صوت غير مرئي كموجه صوتي".
عند إطلاق Beta News ، الأربعاء ، 11 يناير ، أضاف فريق أبحاث Microsoft ، أظهرت النتائج التجريبية أن VALL-E تفوقت بشكل كبير على نظام TTS المتقدم بدون طلقة من حيث طبيعية الكلام وتشابه المتحدث.
"بالإضافة إلى ذلك ، وجدنا أن VALL-E يمكنه الاحتفاظ بمشاعر المتحدث والبيئة الصوتية من الموجه الصوتي في التوليف" ، قال فريق أبحاث Microsoft.
The English, Chinese, Japanese, Arabic, and French versions are automatically generated by the AI. So there may still be inaccuracies in translating, please always see Indonesian as our main language. (system supported by DigitalSiber.id)









