

雅加达 - 微软刚刚推出了一款基于人工智能(AI)的语音模拟器,该模拟器能够在短短三秒钟内听一个人说话后准确模仿他们的声音。
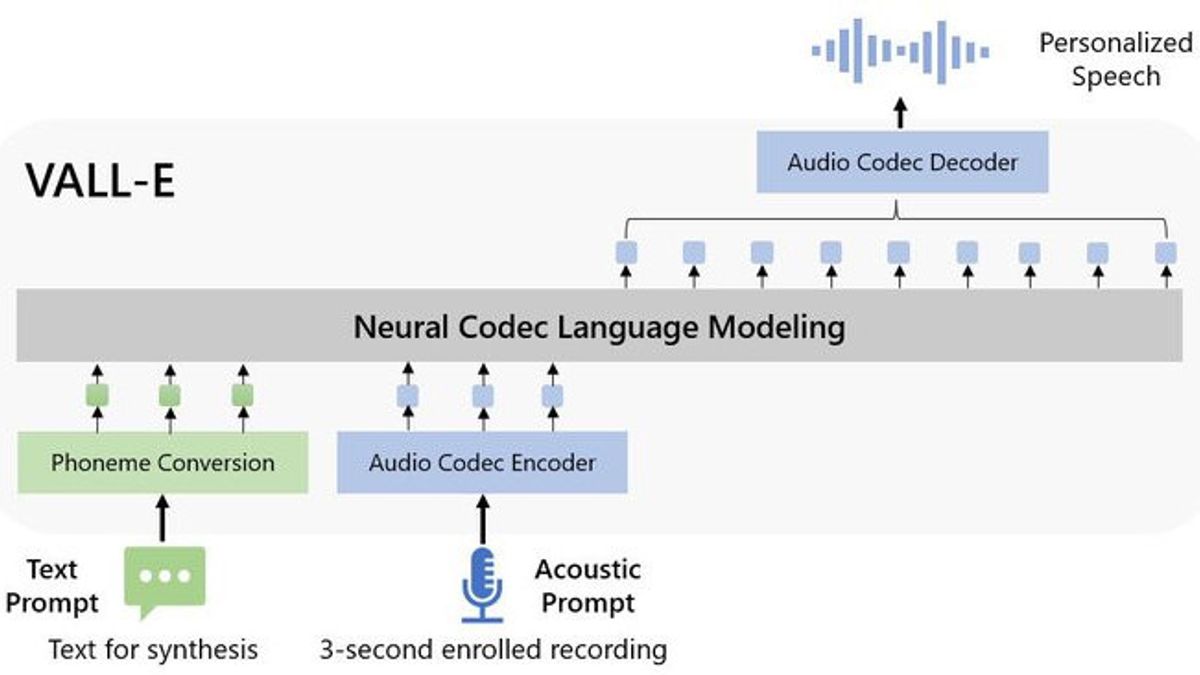
这种神经编解码器讨论模型被称为 VALL-E,是一种由 AI 驱动的高级文本到语音转换 (TTS) 系统。该系统可以训练成像任何人一样说话,仅基于他们三秒钟的声音样本。
“具体来说,我们使用从即用型神经音频编解码器模型派生的离散代码训练VALL-E,并认为TTS是一项条件语言建模任务,而不是像以前的工作那样连续信号回归,”微软研究人员说。
因此,TTS系统听起来非常自然,对现有系统采取了完全不同的方法。
此外,VALL-E 听起来也像人类一样逼真,它能够比以往更好地传达音调和情感。但有人担心,该系统可能用于深度伪造音频。
VALL-E 是使用来自数千人的 60,000 小时音频输入(包括公共领域有声读物)创建和训练的。使用简短的样本,VALL-E能够以以前不可能的方式模仿声音的音调和音色。
“在预训练阶段,我们将TTS训练数据增加到6万小时的英语语音,比现有系统大数百倍,”微软研究人员说。
“VALL-E在上下文中唤起了学习能力,可用于合成高质量的个人语音,只需3秒钟的隐形扬声器注册录音作为声学提示,”他补充说。
微软的研究团队在1月11日星期三推出Beta News时补充说,实验结果表明,VALL-E在语音自然度和说话人相似性方面明显优于先进的零镜头TTS系统。
“此外,我们发现VALL-E可以从合成中的声学提示中保留说话者的情绪和声学环境,”微软研究小组说。
The English, Chinese, Japanese, Arabic, and French versions are automatically generated by the AI. So there may still be inaccuracies in translating, please always see Indonesian as our main language. (system supported by DigitalSiber.id)








