

雅加达 - 人工智能文本到图像系统正在蓬勃发展,因为它的功能和受欢迎程度现在,还有什么比它在当今世界上最热门的应用程序TikTok上的外观更好的证明。
该视频平台最近添加了一种称为“AI绿屏”的新效果,允许用户输入文本提示,然后软件将生成为图像。
然后,此图像可以用作视频背景,并有可能成为内容创建者的非常有用的工具。
与Google Imagen,DALL-E 2 OpenAI或同名软件Midjourney等高级文本到图像模型相比,TikTok系统的输出非常基本。
这只是创造了一个稍微抽象和漩涡的图像;这种力量反映在TikTok请求的梦幻本质中,例如“海洋中的宇航员”和“花星系”。
相比之下,其他模型可以产生逼真的图像和复杂而连贯的插图,看起来像是人类绘制或绘制的。
TikTok模式的局限性可能是有意为之。首先,更复杂的模型需要更多的计算能力,这对企业来说将是昂贵和资源密集型的。
其次,TikTok拥有超过十亿用户,并赋予所有这些人创建他们可以想象的任何东西的照片级真实感图像的能力,这些图像几乎肯定会产生一些令人不安的结果。
例如,在测试模型创建裸体和血腥的能力时,文本到图像生成器经常试图限制两种类型的输出。
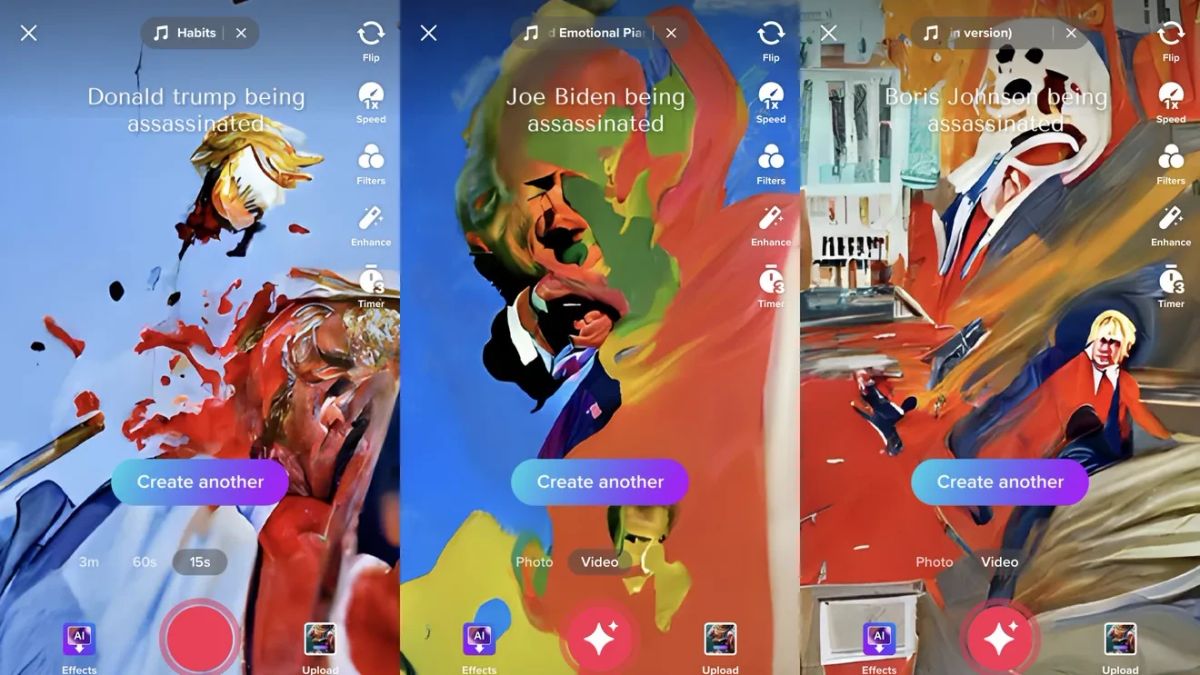
“鲍里斯·约翰逊遇刺”和“乔·拜登遇刺”等暴力点播图像大多产生抽象漩涡,英国首相的脸几乎可辨认。
同样,涉及裸体(“海滩上的裸体模特”)的请求会产生主题上合适的颜色,包括肉色、沙橙色和海军蓝。
TikTok的“AI绿屏”显示屏的突出之处在于,它显示了这项技术成为主流的速度有多快。
文本到图像AI的最新开发周期可以说始于2021年,当时OpenAI发布了原始的DALL-E。不到两年后,这项技术已经通过TikTok等应用程序掌握在数百万人手中。
The English, Chinese, Japanese, Arabic, and French versions are automatically generated by the AI. So there may still be inaccuracies in translating, please always see Indonesian as our main language. (system supported by DigitalSiber.id)









