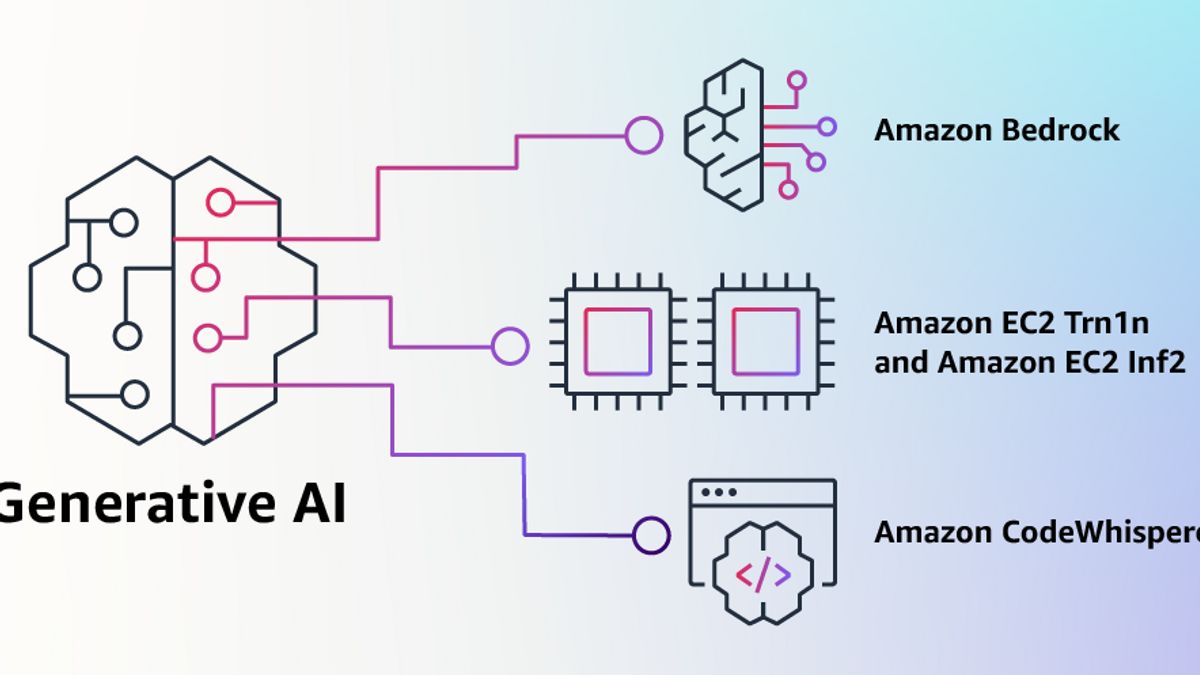


アマゾンウェブサービス(AWS)は、生成人工知能(AI)サービスを拡張して、テクノロジーをより高度化し、クラウドサービスで開発者が利用できるようにしました。
AWSの最新サービスには、AI21 Labsのスタートアップ、Anthropic、Stability AIによって開発されたベースモデルAIのセットとしてプレビューでリリースされたBedrockが含まれます。
ジェネレーティブAIは、会話、ストーリー、画像、ビデオ、音楽など、新しいコンテンツやアイデアを作成できるAIの一種です。ジェネレーティブ AI は、ML モデル、つまり一般に基盤モデル (FM) と呼ばれる大量のデータに対する非常に大規模な事前トレーニング済みモデルを利用しています。
さらに、Bedrockは、テキストと画像の堅牢な範囲のFMにアクセスする機能を提供します。AWS の機械学習責任者である Swami Sivasubramaniam 氏は、お客様は解決したいことに適したモデルを簡単に見つけることができると述べています。
「(彼らはまた)すぐに始め、独自のデータでFMを個人的にカスタマイズし、AWSツールと機能を使用してアプリケーションに簡単に統合して実装することができます」とSivasubramaniamは4月14日金曜日のAWSページから引用して述べています。
現在、Bedrockは、スペイン語、フランス語、ドイツ語、ポルトガル語、イタリア語、オランダ語でテキストを生成するために自然言語の指示に従っているJurassic-2 AI21 Labs、Claude Anthropicなど、テキストを処理および生成できる大規模な言語モデル(LLM)を提供しています。
Bedrockは、安定拡散を含む安定性AIのテキストから画像へのモデルを生成することもできます。Bedrockの最も重要な機能の1つは、モデルのカスタマイズがいかに簡単かということです。
開発者は Amazon S3 のいくつかのラベル付きインスタンスに Bedrock を指定するだけで、サービスは大量のデータに注釈を付けることなく、特定のタスクに合わせてモデルを微調整できます。
さらに、AWSはTitanブランドで独自の基盤の2つのモデルもリリースしました。開発者は、これらの API の背後に独自の生成 AI 搭載製品とサービスを構築し、独自のラベル付き例を提供することで、特定のタスクのモデルを微調整できます。
カスタマイズプロセスにより、企業は漏洩や他の大規模な言語モデルのトレーニングに使用されることを心配することなく、データをより適切に保護および保護できます。
Titan は、データ内の悪意のあるコンテンツを検出して削除し、ユーザー入力内の不適切なコンテンツを拒否し、不適切なコンテンツ (ヘイト スピーチ、冒とく的な表現、暴力など) を含むモデル出力をフィルター処理するために作成されました。
同社はまた、独自のAIチップ、AWS Trainium、およびInferentiaを宣伝して、これらのモデルをクラウドでトレーニングおよび実行しています。
Trainium を搭載した Trn1 インスタンスは、他の EC2 インスタンスに比べてトレーニングコストを最大 50% 節約でき、第 2 世代の 800 Gbps エラスティックファブリックアダプター (EFA) ネットワークに接続された複数のサーバーにトレーニングを分散するように最適化されています。
開発者は、ペタビット規模のネットワークと同じ AWS アベイラビリティーゾーンにある最大 30,000 個の Trainium チップ (6 エクサフロップスを超えるコンピューティング) にスケーリングする UltraCluster で Trn1 インスタンスを実行できます。
最後に、同社はCodeWhispererのAIペアリングプログラミングツールを無料で使用できるようにしました。Python、Java、JavaScript、TypeScript、C#に加えて、Go、Kotlin、Rust、PHP、SQLなどを含む10の新しい言語をサポートするように拡張されました。
The English, Chinese, Japanese, Arabic, and French versions are automatically generated by the AI. So there may still be inaccuracies in translating, please always see Indonesian as our main language. (system supported by DigitalSiber.id)










