

ジャカルタ - AIのテキスト・ツー・イメージ・システムは、その能力と人気が現在、そして現在世界で最もホットなアプリであるTikTokに登場したことよりも優れた証拠のために活況を呈しています。
ビデオプラットフォームは最近、ソフトウェアが画像として生成するテキストプロンプトをユーザーが入力できるようにする「AIグリーンスクリーン」と呼ばれる新しいエフェクトを追加しました。
この画像は、ビデオの背景として使用することができ、コンテンツ制作者にとって非常に便利なツールになる可能性を秘めています。
TikTokのシステムの出力は、Google Imagen、DALL-E 2 OpenAI、または同名のソフトウェアMidjourneyなどの高度なテキストツーイメージモデルと比較して、かなり基本的です。
これは、わずかに抽象的で渦巻くイメージを作成するだけです。「海の宇宙飛行士」や「花の銀河」といったTikTokのリクエストの夢のような性質に反映されている力。
他のモデルは、比較して、フォトリアリスティックな画像や、人間によって描かれたり描かれたりしたように見える複雑で一貫性のあるイラストを生成することができます。
TikTokモデルの制限は意図的なものかもしれない。第 1 に、より洗練されたモデルでは、より多くのコンピューティング パワーが必要であり、企業が実装するにはコストとリソースが大量に消費されます。
第二に、TikTokには10億人以上のユーザーがおり、これらの個人全員に、ほぼ確実に不安な結果を生み出すと想像できるもののフォトリアリスティックな画像を作成する力を与えます。
たとえば、ヌードとゴアを作成するモデルの能力をテストする場合、テキストから画像へのジェネレーターがしばしば制限しようとする2種類の出力。
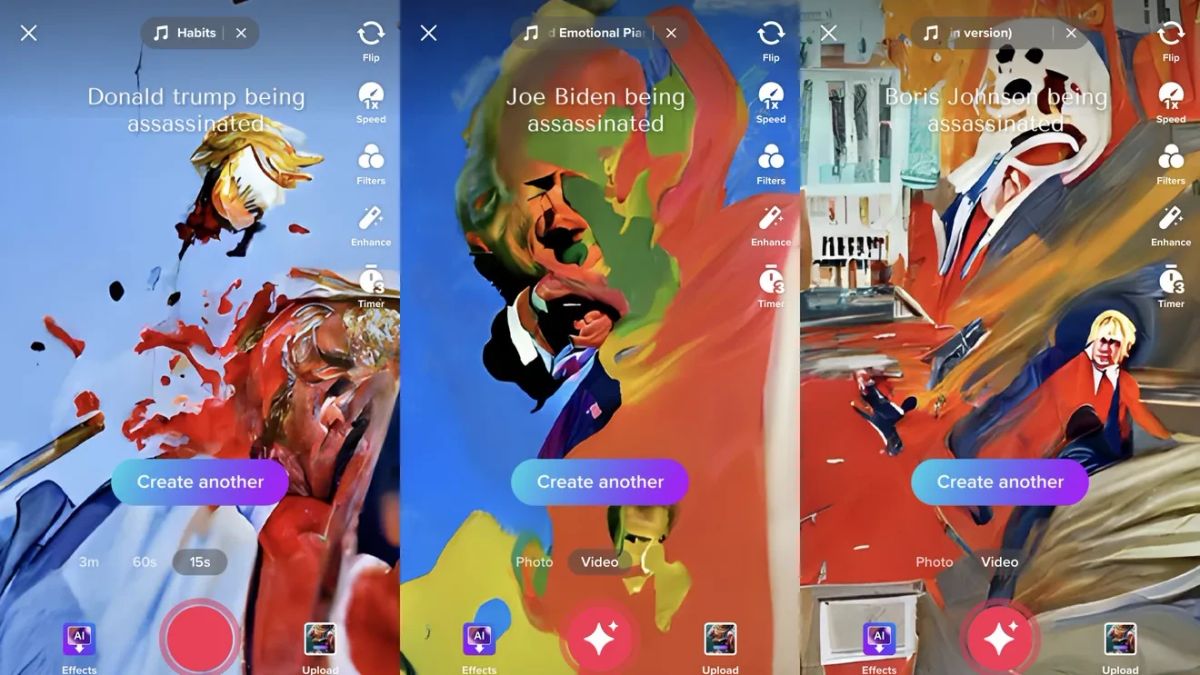
「ボリス・ジョンソン暗殺」や「ジョー・バイデン暗殺」のような暴力的なオンデマンド画像は、ほとんどが抽象的な渦巻きを生み出し、英国首相の顔はほとんど認識できる。
同様に、「ビーチでヌードをモデルにする」というヌードを含むリクエストは、肉の色、砂のオレンジ、紺の青など、テーマ的に適切な色になります。
TikTokの「AIグリーンスクリーン」ディスプレイで際立っているのは、この技術がどれほど速く主流になっているかを示していることです。
テキストから画像へのAIの最新の開発サイクルは、おそらくOpenAIによるオリジナルのDALL-Eのリリースで2021年に始まりました。それから2年も経たないうちに、このテクノロジーはすでにTikTokのようなアプリを通じて何百万人もの人々の手に渡っています。
The English, Chinese, Japanese, Arabic, and French versions are automatically generated by the AI. So there may still be inaccuracies in translating, please always see Indonesian as our main language. (system supported by DigitalSiber.id)








