

ARTA - Apple essaie d’entraîner ses fonctionnalités et ses modèles d’intelligence artificielle (IA) sans dépens de la sécurité de l’utilisateur. Dans son dernier rapport, Apple a révélé comment cela peut être fait.
an, qui est un projet de production d'iPhone et de iPads, a souligné que les utilisateurs utilisent toujours les principes de l'entreprise, qui ne sont pas utilisés de données personnelles ou d'interactions utilisateur uniquement pour former leurs modèles de base. En fait, Apple n’a jamais utilisé de contenu général sur Internet.
Apple a déclaré : « Nous appliquons des filtres pour supprimer des informations permettant d’identifier des données personnelles, telles que des numéros de sécurité sociale et de cartes de crédit », a déclaré Apple, cité mardi 15 avril. « Nous développons de nouvelles techniques... sans divulguer le comportement des individus. »
an, en fonction de l’IA dont Apple parle, c’est Genmoji. La fonction de création d’émoji émouvant, alimentée par Apple Intelligence, utilise une méthode de confidentialité différenciale. Cette méthode est utilisée pour identifier les demandes populaires et les modèles de demande qui ne sont pas liés aux utilisateurs individuels.
Apple utilise actuellement la confidentialité différentielle pour améliorer Genmoji, et dans la prochaine publication, nous utiliserons également cette approche, avec les mêmes protections de protection de la vie privée, pour le terrain d’affichage d’image, le Wand d’image, la création de mémoire et les outils d’écriture d’Apple Intelligence », a déclaré Apple.
Apple améliore également les performances de Genmoji en évaluant les commandes populaires reçues par ses fonctionnalités. En évaluant cela, Apple croit qu’ils peuvent comprendre comment fonctionnent leurs modèles d’IA et améliorer la réponse à la demande.
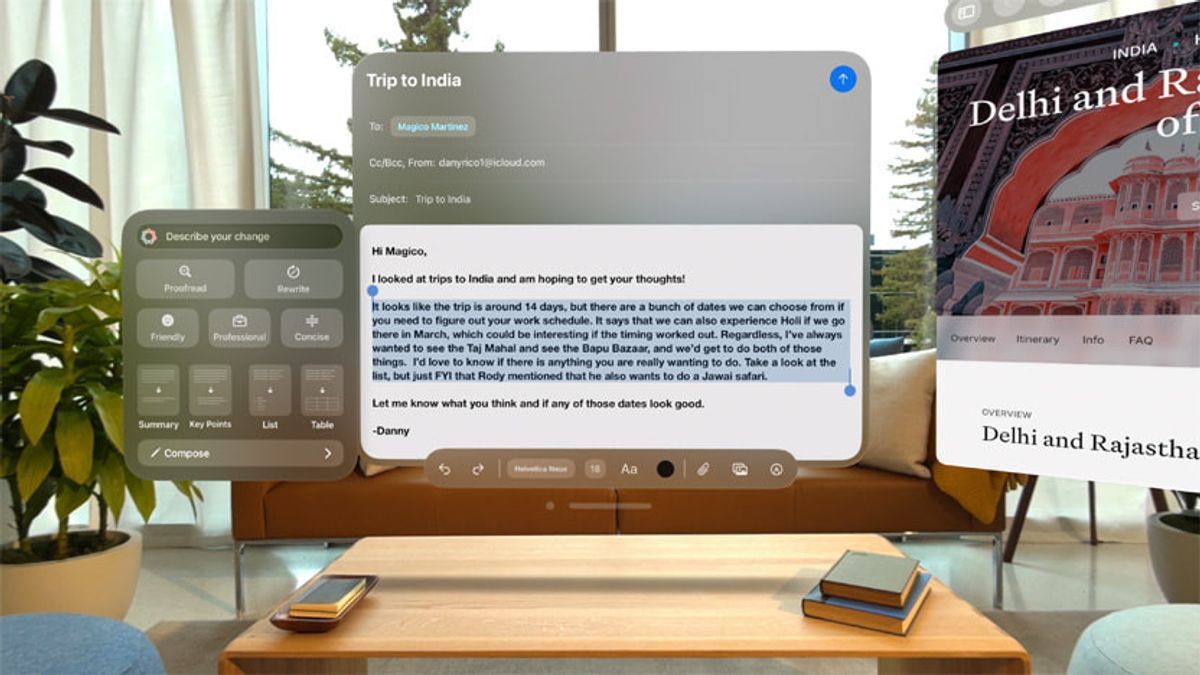
, Apple utilise une nouvelle méthode dans la fonctionnalité de réserve ou d’outils d’écriture qui fonctionnent en phrases longues. La société utilise des données synthétiques créées en imitant un format d’appropriation critique des données utilisateur, sans recueillir du contenu individuel.
ina Dymovski est partagé par notre expérience : « Lors de la création de données synthétiques, notre objectif est de générer des phrases ou des courriels synthétiques assez similaires sur des sujets ou des styles avec des données originales pour aider à améliorer nos modèles de résumtion, mais sans qu’Apple ne recueille des courriels depuis des appareils », a déclaré Apple.
The English, Chinese, Japanese, Arabic, and French versions are automatically generated by the AI. So there may still be inaccuracies in translating, please always see Indonesian as our main language. (system supported by DigitalSiber.id)
Tags les plus populaires
#Prabowo Subianto #Donald Trump #2026 World Cup #venezuela #hut bhayangkara\ #konflik timur tengahPopulaire









