

JAKARTA - Meta has just launched a generative Artificial Intelligence (AI) for audio. Dubbed Voicebox, this technology will make it easier for users to interact in the metaverse, aka the virtual world.
Voicebox can perform speech-making tasks, such as editing, sampling and regulating a style of language that is not specially trained to be done through learning in context.
In addition, Voicebox can produce high-quality audio clips and edit previously recorded audio.
For example, sound the car horn or dog Barking while maintaining content and audio style. Meta's new AI model also adopts multilinguals and produces speech in six languages.
"In the future, multipurpose generative AI models like Voicebox can give a natural sound to virtual assistants and non-players in the metaverse," Meta said in its official blog, quoted on Saturday, June 17.
With Voicebox, visually impaired people can hear written messages from friends read by AI in their voices, create and edit audio tracks for video easily, and more easily.
The following VOI describes the capabilities of Voicebox below.
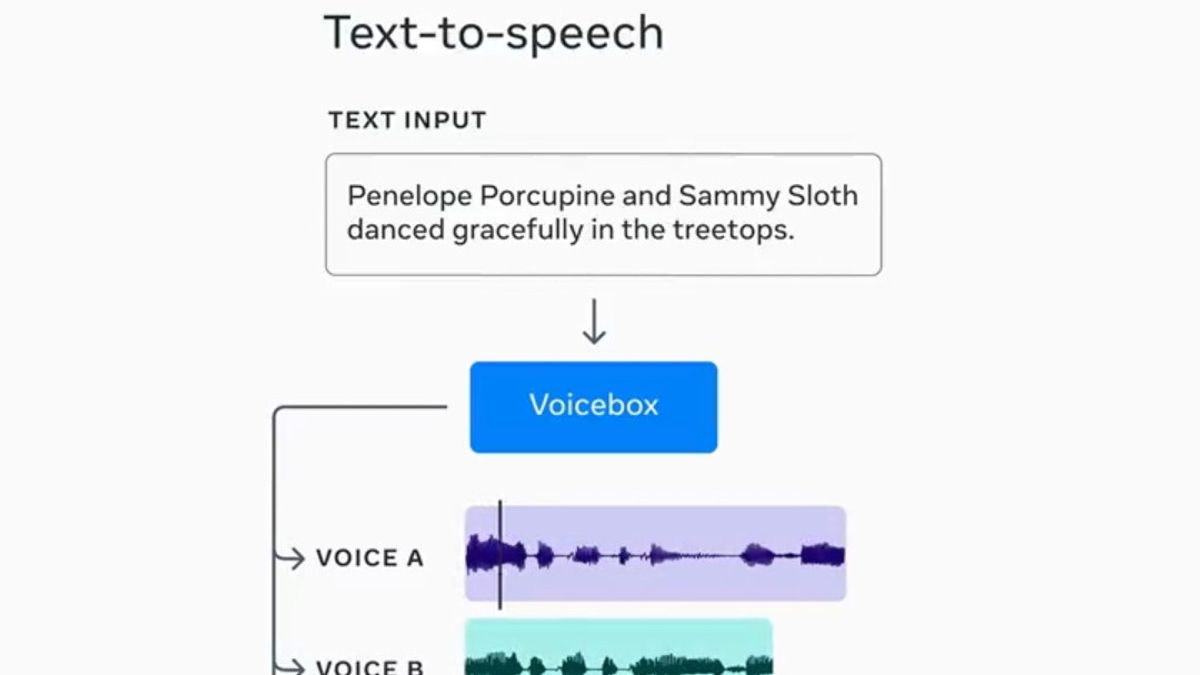
Text-to-Speech Synthesis in Context
Using a two-second audio sample, Voicebox can match the audio style and use it for text-to-speech creation.
Editing Of Speech And Reduction Of Derau
This new AI tool can recreate some of the words that are interrupted by the derau or change the wrong words without having to re-record all the words.
For example, users can identify greeting segments that are interrupted by dog gongongs, cut them, and instruct Voicebox to recreate the segment, such as deleting for audio editing.
Cross-language Style Transfer
Voicebox also adopts multilinguals and produces speech in six languages. When sampled a person's speech and text section in English, French, German, Spanish, Polish, or Portuguese, the new AI tool can produce text reading in one of these languages.
Even speech and text samples in different languages. This ability can be used in the future to help people communicate in a natural and authentic way even if they don't use the same language.
Diverse Speech Sampling
Learning from the various data, Voicebox can produce more representative speech on how people speak in the real world and in the six languages mentioned above.
The English, Chinese, Japanese, Arabic, and French versions are automatically generated by the AI. So there may still be inaccuracies in translating, please always see Indonesian as our main language. (system supported by DigitalSiber.id)





