

JAKARTA - Microsoft has just launched a voice simulator based on Artificial Intelligence (AI), which is capable of accurately imitating someone's voice after listening to them speak in just three seconds.
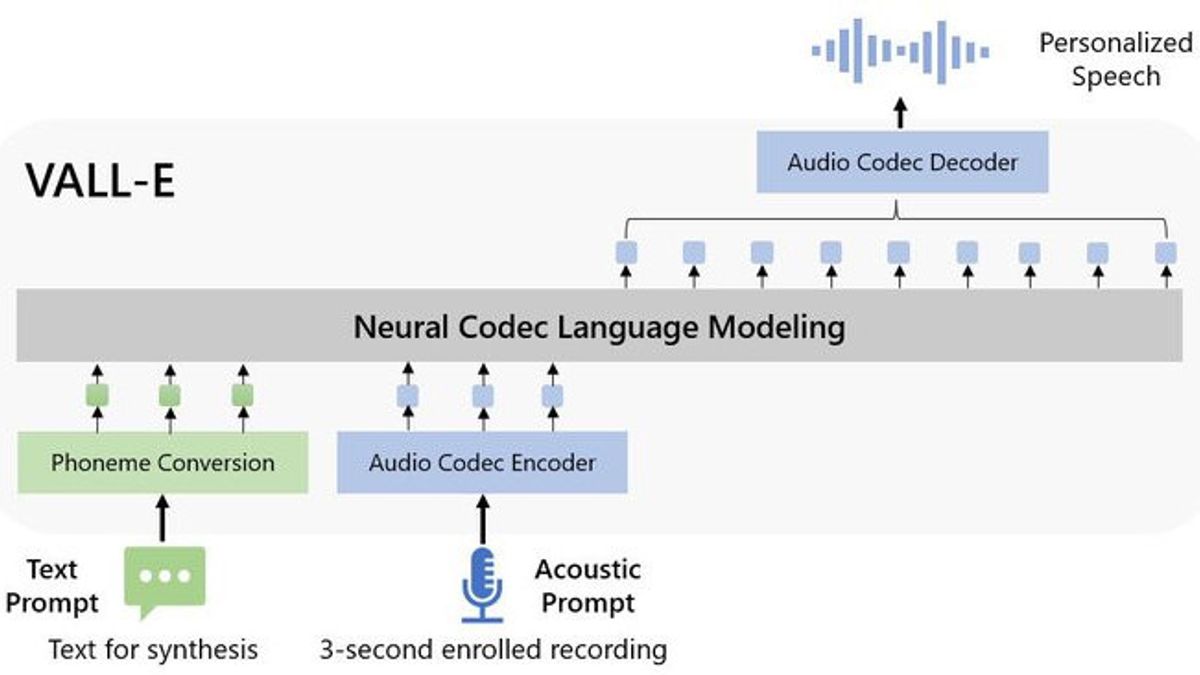
Dubbed VALL-E, this neural codec discussion model is an advanced text-to-speech (TTS) system driven by AI. This system can be trained to speak like anyone based solely on a three-second sample of their voices.
"In particular, we train the VALL-E using discrete codes derived from the ready-to-use neural audio codec model, and regard TTS as a conditional language modeling task rather than continuous signal regression as in previous work," said Microsoft researcher.
As a result, the TTS system sounds very natural taking a completely different approach from existing systems.
In addition, the VALL-E also sounds as realistic as humans, where it is able to convey better tones and emotions than ever before. But there are concerns, the system can be used for deepfake audio.
The VALL-E was created and trained using audio input for 60,000 hours from thousands of people, including public domain audio books. Working with short samples, the VALL-E is able to mimic tones and sound timbres in a way previously impossible.
"During the pre-training stage, we increased the TTS training data to 60 thousand hours of English speech which is hundreds of times bigger than the existing system," said Microsoft researcher.
"VALL-E gives rise to learning capabilities in context and can be used to synthesize high-quality personal greeting with only 3 seconds registered recordings of invisible speakers as acoustic prompts," he added.
Launching Beta News, Wednesday, January 11, Microsoft's research team added, the experimental results showed the VIll-E significantly outperformed the advanced TTS zero-shot system in terms of speech naturality and speaker similarity.
"In addition, we found that the VALL-E can maintain the speaker's emotions and the acoustic environment of the acoustic prompt in synthesis," said Microsoft research team.
The English, Chinese, Japanese, Arabic, and French versions are automatically generated by the AI. So there may still be inaccuracies in translating, please always see Indonesian as our main language. (system supported by DigitalSiber.id)





